15.5.2024

1. Transformer Architektur : Die Transformer Architektur ist eine neuartige Netzwerkarchitektur, die auf Attention-Mechanismen basiert und auf rekurrente und konvolutionale Netzwerke verzichtet. Sie ermöglicht eine bessere Parallelisierung und schnellere Trainingszeiten.
2. Self-Attention und Positional Encoding : Der Self-Attention Mechanismus erfasst die Beziehungen zwischen allen Wörtern in einem Satz unabhängig von ihrer Position. Positional Encoding wird verwendet, um die Reihenfolge der Wörter zu berücksichtigen.
3. Vorteile gegenüber RNNs : Transformer Modelle verarbeiten Eingabesequenzen schneller und effizienter als rekurrente neuronale Netze (RNNs) und können globale Abhängigkeiten besser erfassen, was zu höherer Qualität bei Aufgaben wie maschineller Übersetzung führt.
4. Bekannte Modelle : BERT und GPT sind zwei der bekanntesten Transformer Modelle. BERT ist bidirektional und wird für Textklassifizierung und Named Entity Recognition verwendet, während GPT auto-regressiv ist und für Textgenerierung eingesetzt wird.
5. Anwendungen und Herausforderungen : Transformer Modelle werden in NLP und Computer Vision eingesetzt. Herausforderungen umfassen den hohen Bedarf an Rechenressourcen und die Übernahme von Verzerrungen aus Trainingsdaten. Forscher arbeiten an Lösungen wie FlashAttention und ethischen Überlegungen zur Nutzung der Modelle.
Die Transformer Architektur ist eine neuartige und einfache Netzwerkarchitektur, die ausschließlich auf Attention-Mechanismen basiert und vollständig auf Recurrent (RNNs) und Convolutional Netzwerke (CNNs) verzichtet. Sie wurde von Forschern bei Google entwickelt, um die sequentielle Natur Recurrent Modelle zu überwinden, die eine Parallelisierung beim Verarbeiten von Trainingsbeispielen verhindert.
Durch den Einsatz von Attention-Mechanismen erreicht die Transformer Architektur eine überlegene Qualität bei Aufgaben wie der maschinellen Übersetzung, während sie gleichzeitig besser parallelisierbar ist und deutlich weniger Trainingszeit benötigt. Die Architektur verwendet gestapelte Self-Attention und punktweise, vollständig verbundene Schichten sowohl für den Encoder als auch für den Decoder.
Die Transformer Architektur wurde im Juni 2017 im wegweisenden Paper "Attention is all you need" vorgestellt. Darin demonstrieren die Autoren die Effektivität der Architektur bei Übersetzungsaufgaben. Der Fokus der ursprünglichen Forschung lag auf der Übersetzung, wobei das Transformer-Modell 28,4 BLEU bei der WMT 2014 Englisch-Deutsch-Übersetzungsaufgabe und 41,8 BLEU bei der WMT 2014 Englisch-Französisch-Übersetzungsaufgabe erreichte.
Die Transformer Architektur nutzt Multi-Head-Attention, die es dem Modell ermöglicht, gleichzeitig Informationen aus verschiedenen Repräsentations-Teilräumen an unterschiedlichen Positionen zu berücksichtigen. Dieser Mechanismus erlaubt es dem Transformer, die Beziehungen zwischen allen Wörtern in einem Satz direkt zu modellieren, unabhängig von ihrer jeweiligen Position.
Um Informationen über die relative oder absolute Position der Token in der Sequenz einzubringen, verwendet der Transformer das sogenannte Positional Encoding. Dies ist notwendig, da das Modell keine Rekurrenz und keine Faltung enthält. Der Encoder und der Decoder in der Transformer Architektur bestehen jeweils aus einem Stapel von sechs identischen Schichten, die die Eingabesequenz iterativ verarbeiten und eine kontextuelle Repräsentation erzeugen.
Das Herzstück der Transformer Architektur ist der Self-Attention Mechanismus. Dieser ermöglicht es dem Modell, die Beziehungen und Abhängigkeiten zwischen allen Wörtern in einem Satz zu erfassen, unabhängig von ihrer Position. Dabei wird jedem Wort eine Gewichtung zugewiesen, die seine Relevanz im Kontext des gesamten Satzes widerspiegelt. So kann der Transformer die Bedeutung einzelner Wörter besser verstehen und ihre Rolle im Satzgefüge erkennen.
Da der Transformer im Gegensatz zu rekurrenten neuronalen Netzen (RNNs) keine sequenzielle Verarbeitung der Wörter vornimmt, benötigt er eine andere Methode, um die Positionsinformationen der einzelnen Wörter zu berücksichtigen. Hierfür wird das sogenannte Positional Encoding eingesetzt. Dabei werden die Eingabewörter mit Positionsvektoren kombiniert, die Informationen über ihre relative oder absolute Position im Satz enthalten. Auf diese Weise kann der Transformer die Reihenfolge der Wörter in seine Berechnungen einbeziehen, ohne auf eine schrittweise Verarbeitung angewiesen zu sein.
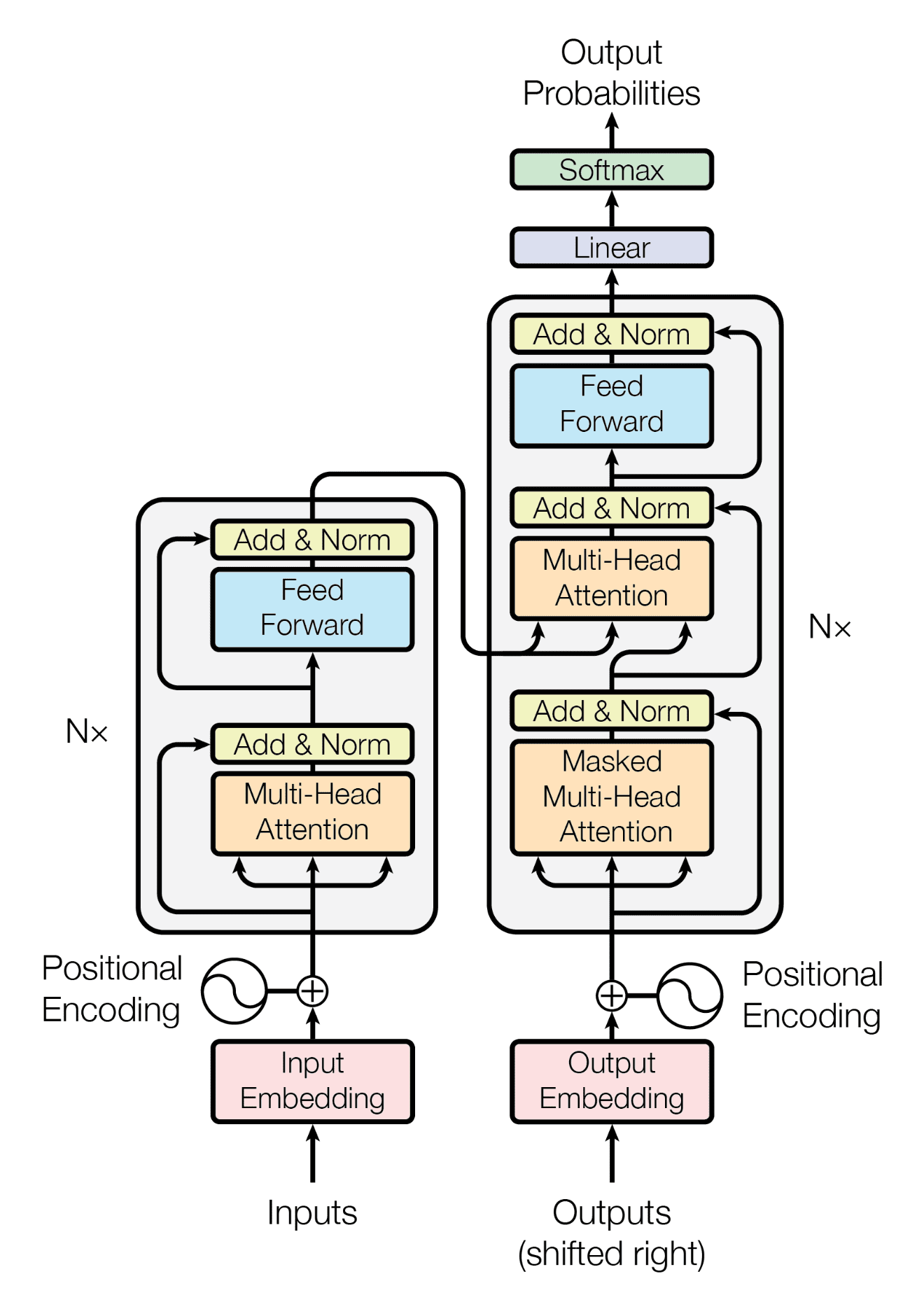
Die Transformer Architektur besteht aus zwei Hauptkomponenten: dem Encoder und dem Decoder. Der Encoder verarbeitet die Eingabesequenz und erzeugt eine kontextuelle Repräsentation jedes Wortes unter Berücksichtigung aller anderen Wörter im Satz. Dazu durchläuft die Eingabesequenz mehrere Schichten von Self-Attention und Feed-Forward Netzwerken. Jede Schicht wendet dabei die gleichen Operationen auf alle Wörter parallel an und reichert ihre Repräsentationen mit Kontextinformationen an.
Der Decoder generiert basierend auf der Encoderausgabe die Zielsequenz, also beispielsweise die Übersetzung in eine andere Sprache. Auch hier kommen mehrere Schichten von Self-Attention und Feed-Forward Netzwerken zum Einsatz. Zusätzlich verfügt der Decoder über einen Attention-Mechanismus, der es ihm ermöglicht, sich auf relevante Teile der Encoderausgabe zu konzentrieren. Dabei wird in jedem Schritt entschieden, welche Informationen aus dem Eingabesatz für die Generierung des nächsten Wortes in der Zielsequenz wichtig sind.
Im Vergleich zu traditionellen rekurrenten neuronalen Netzen bietet die Transformer Architektur mehrere entscheidende Vorteile. Durch den Verzicht auf sequenzielle Verarbeitung und den Einsatz von Self-Attention können Transformer Modelle Eingabesequenzen deutlich schneller und effizienter verarbeiten. Die parallele Berechnung ermöglicht eine bessere Nutzung moderner Hardware wie GPUs und beschleunigt das Training um ein Vielfaches. Darüber hinaus können Transformer durch die direkte Modellierung von Wortbeziehungen über lange Distanzen hinweg Abhängigkeiten besser erfassen als RNNs, die Informationen schrittweise propagieren müssen. Diese Fähigkeit zur globalen Kontexterfassung führt zu einer höheren Qualität bei Aufgaben wie maschineller Übersetzung oder Sprachverständnis.
Es gibt verschiedene Arten von Transformer Modellen, die sich in ihrer Architektur und Funktionsweise unterscheiden. Die drei Hauptkategorien sind:
Die Transformer Architektur hat sich zu einem Grundpfeiler des modernen Natural Language Processing entwickelt. Transformer Modelle werden für eine Vielzahl von NLP-Aufgaben eingesetzt, darunter:
Doch die Anwendungen der Transformer Architektur beschränken sich nicht nur auf die Verarbeitung natürlicher Sprache. Auch im Bereich Computer Vision werden Transformer eingesetzt, beispielsweise für Aufgaben wie Bilderkennung und -segmentierung. Die Fähigkeit der Transformer, globale Abhängigkeiten zu modellieren, erweist sich auch bei der Analyse visueller Daten als vorteilhaft.
Zwei der bekanntesten Transformer Modelle sind BERT (Bidirectional Encoder Representations from Transformers) und GPT (Generative Pre-trained Transformer).
BERT wurde von Google entwickelt und 2018 veröffentlicht. Es handelt sich um ein bidirektionales Transformer Modell, das auf großen Textkorpora vortrainiert wurde. Durch die bidirektionale Verarbeitung kann BERT den Kontext von beiden Seiten eines Wortes erfassen und so ein tieferes Verständnis des Textes erlangen. BERT erreichte neue Bestwerte bei einer Reihe von NLP-Benchmarks und hat die Entwicklung zahlreicher darauf aufbauender Modelle inspiriert.
GPT wurde von OpenAI entwickelt und ist ein auto-regressives Sprachmodell. Es wird verwendet, um Texte zu generieren, indem es das nächste Wort basierend auf den vorherigen Wörtern vorhersagt. GPT-3, die dritte Generation des Modells, verfügt über 175 Milliarden Parameter und kann beeindruckend menschenähnliche Texte erzeugen. Es hat gezeigt, dass Transformer Modelle in der Lage sind, ein breites Spektrum an Aufgaben zu bewältigen, oft ohne explizites Training für die spezifische Aufgabe (Few-Shot Learning).
Ein entscheidender Aspekt der Transformer Architektur ist das Transfer Learning. Dabei werden Modelle zunächst auf großen, ungelabelten Datensätzen vortrainiert und dann für spezifische Aufgaben feinabgestimmt. Dieser Ansatz ermöglicht es, das in den Daten enthaltene Wissen auf neue Probleme zu übertragen und mit weniger gelabelten Daten gute Ergebnisse zu erzielen.
Die Tokenisierung spielt ebenfalls eine wichtige Rolle in Transformer Modellen. Dabei wird der Eingabetext in numerische Repräsentationen, sogenannte Token, umgewandelt. Jedes Token wird dann über eine Worteinbettungstabelle in einen Vektor konvertiert. Diese Vektoren dienen als Eingabe für das Transformer Modell und ermöglichen es ihm, die Bedeutung und Beziehungen der Wörter zu erfassen.
Die Transformer Architektur hat sich in der Praxis als äußerst leistungsfähig und vielseitig erwiesen. Ihre Implementierung erfordert jedoch sorgfältige Überlegungen hinsichtlich der Ressourcen und der Skalierbarkeit. Ein entscheidender Vorteil der Transformer ist, dass sie weniger Rechenaufwand beim Training benötigen und besser für moderne Machine-Learning-Hardware geeignet sind. Dadurch kann die Trainingszeit um bis zu eine Größenordnung beschleunigt werden.
Die Implementierung der Transformer erfolgt typischerweise in zwei Phasen: Pre-Training und Fine-Tuning. Beim Pre-Training wird das Modell auf großen, ungelabelten Datensätzen trainiert, um ein allgemeines Verständnis für Sprache zu entwickeln. Anschließend wird es für spezifische Aufgaben feinabgestimmt. Dieser Ansatz des Transfer Learnings ermöglicht die Anwendung eines einzigen Modells auf ein breites Spektrum von Aufgaben.
Trotz ihrer Erfolge sind Transformer nicht frei von Herausforderungen. Eine davon ist der hohe Bedarf an Rechenressourcen, insbesondere während des Trainings. Die Komplexität der Attention-Mechanismen wächst quadratisch mit der Sequenzlänge, was die Skalierbarkeit auf sehr lange Sequenzen erschwert. Forscher arbeiten an Lösungen wie der FlashAttention, die Hardware-Funktionen und algorithmische Fortschritte nutzt, um den Attention-Mechanismus effizienter zu gestalten.
Eine weitere Herausforderung besteht darin, dass Transformer Verzerrungen und Vorurteile aus ihren Trainingsdaten übernehmen können. Da die Modelle auf riesigen Textkorpora trainiert werden, spiegeln sie potenziell auch gesellschaftliche Vorurteile wider. Um dem entgegenzuwirken, sind sorgfältige Datenauswahl, Bias-Erkennung und -Korrektur sowie ethische Überlegungen beim Einsatz von Transformer-Modellen unerlässlich.
Die Transformer Architektur hat das Feld des Deep Learning revolutioniert und die Möglichkeiten der Verarbeitung natürlicher Sprache erweitert. Aktuelle Entwicklungen konzentrieren sich darauf, die Effizienz und Skalierbarkeit der Transformer weiter zu verbessern. Ansätze wie lineare RNNs, die als Faltungen umformuliert werden können, oder Jamba, das eine dreimal höhere Durchsatzleistung bei langen Kontexten im Vergleich zu Transformer-basierten Modellen ähnlicher Größe bietet, zeigen vielversprechende Fortschritte.
Darüber hinaus werden Transformer-Architekturen auch auf andere Bereiche wie Computer Vision und multimodale Verarbeitung ausgeweitet. Die Fähigkeit der Transformer, globale Zusammenhänge zu modellieren und Informationen aus verschiedenen Quellen zu integrieren, eröffnet neue Möglichkeiten für die Analyse und das Verständnis komplexer Daten.
Mit der rasanten Entwicklung der Transformer Architektur und den ständigen Innovationen im Bereich des Deep Learnings ist zu erwarten, dass Transformer auch in Zukunft eine zentrale Rolle bei der Verarbeitung natürlicher Sprache und darüber hinaus spielen werden. Dabei gilt es, die Herausforderungen zu meistern und die Potenziale dieser leistungsstarken Architektur verantwortungsvoll zu nutzen.
Die Transformer Architektur hat die Textgenerierung revolutioniert. Durch den Einsatz von Self-Attention und Positional Encoding können Transformer Modelle wie GPT lange, kohärente Texte erzeugen, die oft kaum von menschlich geschriebenen zu unterscheiden sind. Der Schlüssel liegt in der Fähigkeit der Transformer, den Kontext auf Satzebene zu erfassen und die Beziehungen zwischen den Wörtern unabhängig von ihrer Position zu modellieren. So können sie die Bedeutung und Rolle einzelner Wörter im Gesamtkontext besser verstehen und beim Generieren berücksichtigen.
Ein beeindruckendes Beispiel für die Leistungsfähigkeit von Transformern in der Textgenerierung ist GPT-3 von OpenAI. Mit 175 Milliarden Parametern ist es in der Lage, Texte zu einer Vielzahl von Themen zu generieren, die oft verblüffend menschenähnlich wirken. Dabei zeigt GPT-3 ein bemerkenswertes Verständnis für Kontext und Zusammenhänge. Es kann sogar Aufgaben bewältigen, für die es nicht explizit trainiert wurde, wie das Beantworten von Fragen oder das Schreiben von Code.
Die Qualität der generierten Texte hängt jedoch stark von den Trainingsdaten ab. Da Transformer auf riesigen Textkorpora trainiert werden, können sie auch Verzerrungen und Vorurteile aus diesen Daten übernehmen. Sorgfältige Datenauswahl und Nachbearbeitung sind daher wichtig, um hochwertige und ethisch vertretbare Ergebnisse zu erzielen. Im Vergleich zu traditionellen Methoden wie regelbasierten Systemen oder Markov-Ketten bieten Transformer jedoch eine deutlich höhere Flexibilität, Kohärenz und Kontextbezogenheit in der Textgenerierung.
Die rasante Entwicklung der Transformer Architektur lässt erwarten, dass die Qualität und Vielseitigkeit generierter Texte in Zukunft weiter zunehmen wird. Aktuelle Forschungen konzentrieren sich darauf, die Effizienz und Skalierbarkeit der Modelle zu verbessern, um noch längere Kontexte verarbeiten zu können. Auch die Integration von Weltwissen und Reasoning-Fähigkeiten ist ein wichtiges Ziel, um die generierten Texte inhaltlich fundierter und logisch konsistenter zu machen.
Gleichzeitig gilt es, die ethischen Herausforderungen im Blick zu behalten. Dazu gehören Fragen der Verantwortlichkeit und Transparenz beim Einsatz von Textgenerierung, etwa in Journalismus oder Bildung. Auch die Gefahr des Missbrauchs, beispielsweise durch die Verbreitung von Fake News oder Propaganda, muss adressiert werden. Insgesamt bietet die Transformer Architektur jedoch enormes Potenzial, die Kommunikation zwischen Mensch und Maschine natürlicher und effektiver zu gestalten und kreative Anwendungen in vielen Bereichen zu ermöglichen.
1. Was ist die Transformer Architektur im Machine Learning?
Die Transformer Architektur ist eine neuartige Netzwerkarchitektur, die ausschließlich auf Attention-Mechanismen basiert und vollständig auf rekurrente und konvolutionale Netzwerke verzichtet. Sie wurde entwickelt, um die inhärent sequentielle Natur rekurrenter Modelle zu überwinden und ermöglicht eine bessere Parallelisierung und schnellere Trainingszeiten.
2. Was sind die Hauptkomponenten der Transformer Architektur?
Die Hauptkomponenten der Transformer Architektur sind der Encoder und der Decoder. Der Encoder verarbeitet die Eingabesequenz und erzeugt eine kontextuelle Repräsentation jedes Wortes, während der Decoder basierend auf der Encoderausgabe die Zielsequenz generiert. Beide bestehen aus mehreren Schichten von Self-Attention und Feed-Forward Netzwerken.
3. Welche Vorteile bietet die Transformer Architektur gegenüber RNNs?
Die Transformer Architektur bietet mehrere Vorteile gegenüber traditionellen rekurrenten neuronalen Netzen (RNNs), darunter schnellere und effizientere Verarbeitung von Eingabesequenzen durch parallele Berechnung, bessere Nutzung moderner Hardware wie GPUs und eine höhere Qualität bei der Modellierung von Wortbeziehungen über lange Distanzen hinweg.
4. Welche Arten von Transformer Modellen gibt es und wofür werden sie verwendet?
Es gibt verschiedene Arten von Transformer Modellen, darunter:
- GPT-artige (auto-regressive) Modelle: Für Textgenerierung.
- BERT-artige (auto-encoding) Modelle: Für Textklassifizierung und Named Entity Recognition.
- BART/T5-artige (sequence-to-sequence) Modelle: Für Aufgaben wie Zusammenfassung und Übersetzung.
5. Welche Anwendungen haben Transformer Modelle im NLP und Computer Vision?Transformer Modelle werden in einer Vielzahl von NLP-Aufgaben eingesetzt, darunter maschinelle Übersetzung, Textgenerierung, Textklassifizierung und Named Entity Recognition. Sie finden auch Anwendung im Bereich Computer Vision, beispielsweise bei der Bilderkennung und -segmentierung.
6. Was sind BERT und GPT und wie unterscheiden sie sich?
BERT (Bidirectional Encoder Representations from Transformers) ist ein bidirektionales Transformer Modell, das den Kontext von beiden Seiten eines Wortes erfasst und für Aufgaben wie Textklassifizierung verwendet wird. GPT (Generative Pre-trained Transformer) ist ein auto-regressives Sprachmodell, das Texte generiert, indem es das nächste Wort basierend auf den vorherigen Wörtern vorhersagt.
7. Welche Herausforderungen gibt es bei der Implementierung der Transformer Architektur?
Zu den Herausforderungen gehören der hohe Bedarf an Rechenressourcen, insbesondere während des Trainings, und die Skalierbarkeit auf sehr lange Sequenzen. Zudem können Transformer Modelle Verzerrungen und Vorurteile aus ihren Trainingsdaten übernehmen, was sorgfältige Datenauswahl und ethische Überlegungen erfordert.